TL;DR
GazeGen은 Harvard와 Meta Reality Labs Research가 개발한 시스템으로, 사용자의 시선을 이용해 AR 환경에서 콘텐츠를 생성하고 조작할 수 있는 새로운 상호작용 방식을 제공한다. 주요 기술인 DFT Gaze는 Knowledge Distillation과 Masked Autoencoder로 경량화된 모델이며, 적은 파라미터로도 높은 정확도를 유지한다. GazeGen은 사용자가 시선을 통해 객체를 추가, 삭제, 재배치하는 편집을 가능하게 하고, Midas Touch 문제를 해결하기 위해 Trigger Mechanism을 도입해 의도하지 않은 조작을 방지한다. 시스템은 AR 및 VR 환경에서 사용자의 비언어적 의도를 실시간으로 파악해 사용자 경험을 확장할 가능성을 보여주며, 향후 3D 상호작용과 연산 효율성 향상을 목표로 한다.
GazeGen: Gaze-Driven User Interaction for Visual Content Generation
Harvard와 Meta Reality Labs Research의 연구진이 발표한 GazeGen 시스템은 사용자의 시선을 활용하여 콘텐츠를 생성하고 조작할 수 있는 혁신적인 상호작용 방식을 제공한다. 이 시스템은 특히 물리적 조작이 어려운 상황에서의 사용자 경험을 크게 향상시키며, AR(증강 현실) 환경에서도 자연스러운 콘텐츠 조작을 가능하게 한다.

연구 배경
기존 시선 추적 기술은 사용자의 시선을 따라 정보를 수집하는 데 중점을 두었다면, GazeGen은 시선을 콘텐츠 조작의 인터페이스로 활용하여, 사용자에게 더 직관적이고 접근성 높은 상호작용 경험을 제공하는 것이 목표이다. 이는 시선만으로도 이미지 또는 비디오에 대한 조작이 가능해 물리적 제약이 있는 사용자를 위한 접근성 개선 효과도 기대된다.
GazeGen 시스템 구조 및 주요 기법
1. DFT Gaze Agent
GazeGen의 핵심 기술은 DFT Gaze(Distilled and Fine-Tuned Gaze)라는 초경량 시선 추적 모델이다.
기존의 시선 추적 시스템은 보통 높은 정확도를 위해 수백만 개 이상의 파라미터를 사용하는 복잡한 모델로 구성되는데, 이로 인해 고사양의 하드웨어가 필수적이었다. 반면, 이 논문에서 제시한 DFT Gaze Agent는 Knowledge Distillation과 Masked Autoencoder 기술을 통해, 281K 파라미터만으로도 대형 모델의 성능을 구현하였다. Knowledge Distillation을 통해 ConvNeXt V2-A의 복잡한 네트워크를 간소화하였으며, 다양한 데이터에서 학습된 고성능 특성을 유지하면서도 채널 차원을 줄여 연산 효율을 극대화했다.

DFT Gaze는 실시간 gaze prediction을 목표로 하여, Raspberry Pi 4와 같은 소형 엣지 디바이스에서도 평균 426.66ms의 낮은 latency로 작동할 수 있다. 이를 통해 낮은 사양의 장치에서도 원활한 상호작용이 가능하다.
2. Personalized Gaze Estimation
DFT Gaze는 Adapter 모듈을 사용하여 사용자 별로 시선 패턴에 맞춘 개인화된 예측을 가능하게 한다. Adapter는 두 개의 fully-connected layers, BatchNorm, LeakyReLU activation으로 구성되어 있으며, 이를 통해 최소한의 시선 데이터(개인별 5개 이미지)만으로도 개인화가 가능하다.
이 방식은 기존의 시선 추적 모델들이 일반적으로 사용자 독립적(generalized)으로 학습되기 때문에 사용자 개별 특성에 맞춘 조정이 어려운 점과 대비된다. DFT Gaze는 개인화된 모델로의 빠른 적응을 가능하게 하여, 사용자에게 맞춤형 시선 추적 경험을 제공할 수 있다.
Midas Touch 문제 해결을 위한 Trigger Mechanism
GazeGen은 사용자의 시선을 활용한 조작에서 발생할 수 있는 Midas Touch 문제를 해결하기 위해 다음과 같은 Trigger Mechanism을 도입했다.
Midas Touch 문제란?
시선을 기반으로 하는 상호작용에서, 사용자가 특정 객체를 지나쳐 보는 것만으로도 의도하지 않은 조작이 발생하는 문제를 뜻한다. 이름은 그리스 신화의 미다스(Midas) 왕이 손에 닿는 모든 것을 황금으로 바꾸게 된 이야기에 유래하였다.
GazeGen 시스템에서는 사용자의 시선이 단순히 지나가는 것만으로 의도치 않은 조작이 일어나지 않도록 여러 가지 기법을 사용한다. 먼저, Fixation duration requirement을 두어 사용자가 특정 객체를 일정 시간 이상 응시해야 조작이 활성화되도록 했다. 이렇게 하면, 사용자가 스쳐 지나가는 시선에 의해 실수로 조작이 이루어지는 일을 방지할 수 있다.
또한, Gaze position filtering 기능을 통해 시선의 중심과 주변을 구분하여 특정 객체에 정확히 초점을 맞출 때만 조작이 이루어지도록 한다. 이를 통해 사용자가 실제로 집중하여 보고 있는 객체에 대해서만 상호작용이 활성화된다.
마지막으로, User-adaptable sensitivity adjustment 기능을 도입하여, 사용자의 gaze pattern에 따라 조작 민감도를 조절할 수 있다. 이로써 각 사용자에게 최적화된 시선 기반 인터랙션 경험을 제공하며, 개인별로 더욱 직관적이고 편리한 사용자 경험을 가능하게 한다.
GazeGen의 핵심 기능
기존의 시선 추적 시스템은 주로 사용자의 시선을 추적하고 그 위치를 파악하는 데 중점을 두어, 단순히 시선 데이터를 기록하거나 분석하는 용도로 사용되었다. 그러나 GazeGen은 단순한 시선 추적을 넘어, Real-Time Gaze-Driven Object Detection and Content Manipulation 기능을 통해 시선을 이용한 콘텐츠 조작을 가능하게 한다는 점에서 차별화된다. GazeGen은 사용자가 바라보는 객체를 실시간으로 탐지하고 이를 활용해 다양한 편집 작업을 수행할 수 있다.

예를 들어, 사용자는 시선을 통해 객체를 추가, 삭제, 재배치하거나 스타일을 변경하는 등 복잡한 콘텐츠 편집을 수행할 수 있으며, 이러한 조작은 Stable Diffusion 모델을 활용하여 객체의 mask와 bounding box를 실시간으로 생성하여 시각적 일관성과 자연스러움을 극대화한다. 이로 인해, 사용자는 AR 환경과 디지털 디자인 플랫폼에서 시선만으로도 직관적이고 정밀한 콘텐츠 조작을 경험할 수 있게 된다.
또한, GazeGen은 Gaze-Driven Video Generation 기능을 통해 사용자의 시선을 기반으로 정적인 이미지를 동영상으로 변환하거나 특정 객체를 애니메이션화하는 것도 가능하게 한다. Text-to-Video (T2V) 모델을 사용하여 사용자가 바라보는 객체를 애니메이션화할 수 있으며, 이로써 gaze tracking과 AR 콘텐츠 간의 실시간 상호작용이 가능해진다. 이러한 기능은 기존의 시선 추적 시스템이 단순히 시선 정보를 제공하는 데 그쳤던 한계를 넘어, 사용자 시선을 기반으로 한 동적 콘텐츠 생성 및 편집을 가능하게 하며, 다양한 시나리오에서 창의적인 비디오 생성의 가능성을 제공한다.
실험 설정 및 결과
GazeGen의 DFT Gaze 모델은 다양한 실험을 통해 기존 모델보다 더 효율적이고 높은 성능을 보여주었다. 이 실험은 AEA와 OpenEDS2020 데이터셋을 활용해 일반화된(generalized) 시선 추적 성능과 개인화된(personalized) 시선 추적 성능을 평가하는 방식으로 진행되었다.
AEA 데이터셋은 일상적인 활동 중 사용자의 시선을 기록한 데이터셋으로, 모델이 다양한 각도와 거리에서 실제 사용자의 시선을 얼마나 정확히 추적할 수 있는지를 평가할 수 있도록 설계되어 있다. OpenEDS2020 데이터셋은 VR 환경에서 수집된 3D 시선 데이터를 제공하며, 가상현실 환경과 같은 폐쇄형 환경에서의 시선 추적 성능을 평가하는 데 활용된다. 이 두 데이터셋은 각각 일상적이고 자연스러운 시선 추적과 특정 환경에서의 정밀한 시선 추적 능력을 평가하는 데 중요한 자료로 사용된다.
일반화된(generalized) 시선 추적 성능은 사용자의 특성에 맞춘 조정을 거치지 않고 다양한 사용자에게 공통적으로 적용할 수 있는 모델의 성능을 의미하며, 이때 성능 지표로는 예측된 시선과 실제 시선 간의 각도 차이를 나타내는 평균 시선 오차(angular gaze error)가 사용된다. 이 값이 낮을수록 시선 예측의 정확도가 높음을 의미한다.

실험 결과, DFT Gaze의 Teacher Model로 사용된 ConvNeXt V2-A 모델은 AEA 데이터셋에서 1.94°, OpenEDS2020에서 6.90°의 평균 시선 오차를 기록하며 높은 정확도를 보였다. DFT Gaze 모델은 AEA에서 2.14°, OpenEDS2020에서 7.82°로 ConvNeXt V2-A에 근접한 성능을 유지했는데, 이는 DFT Gaze가 단 281K 파라미터만으로도 약 12.8배 큰 3.6M 파라미터의 ConvNeXt V2-A와 비슷한 정확도를 구현했다는 점에서 큰 의의를 지닌다.
개인화된(personalized) 시선 추적 성능은 사용자 개인의 시선 패턴에 맞춰 조정된 모델이 얼마나 정확하게 예측할 수 있는지를 평가하는 것으로, 이 경우에도 평균 시선 오차가 성능 지표로 사용된다.

개인화된 설정에서 ConvNeXt V2-A 모델은 AEA 데이터셋에서 2.32°, OpenEDS2020에서 5.36°의 오차를 보였으며, DFT Gaze 모델은 AEA에서 2.60°, OpenEDS2020에서 5.80°로 ConvNeXt V2-A에 근접한 정확도를 보여주었다. 이로써 DFT Gaze는 경량화된 모델임에도 불구하고 개인 맞춤형 예측에서도 높은 성능을 유지할 수 있음을 확인할 수 있었다.
결론적으로, DFT Gaze는 AEA와 OpenEDS2020이라는 서로 다른 특성을 지닌 데이터셋에서 ConvNeXt V2-A에 근접한 성능을 보였으며, 약 12.8배 적은 파라미터를 사용해 유사한 정확도를 구현했다는 점에서 의의를 보였다. 또한, 정성적 실험을 통해 GazeGen이 제공하는 시선 기반 콘텐츠 생성과 조작의 가능성을 직접적으로 확인할 수 있었으며, 사용자 시선을 직관적인 상호작용 도구로 활용하는 새로운 사용자 경험을 제시했다. 이를 통해 GazeGen의 DFT Gaze는 다양한 환경에서도 유연하게 활용할 수 있는 효율적이고 혁신적인 시선 추적 솔루션임을 입증했다.
한계점 및 향후 과제
GazeGen 논문은 DFT Gaze 모델의 성능과 가능성을 보여주었지만, 몇 가지 한계와 향후 개선 가능성도 제시하고 있다.
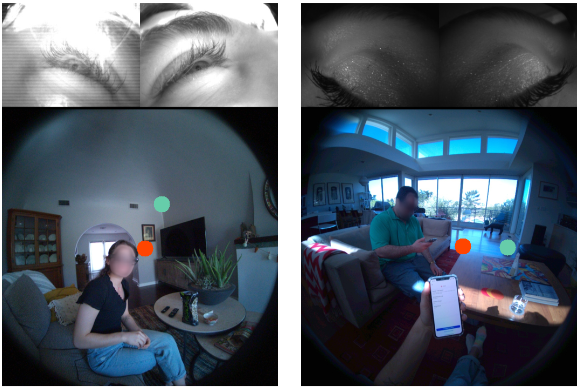
먼저, lighting and reflective conditions에서의 제약이 있다. DFT Gaze는 다양한 조명 조건에서 시선 추적이 가능하지만, 밝은 조명이나 반사 환경에서는 gaze prediction 정확도가 떨어질 수 있어 안정적 성능 보장이 어렵다. 또한, depth information and 3D object manipulation에서 제한이 있어, 현재 주로 2D 기반으로 수행되는 객체 편집이 3D 공간에서의 현실감을 충분히 제공하지 못하는 한계가 있다.
personalization initialization 과정에서도 최소한의 개인 데이터를 필요로 하는 초기화 시간이 요구되어, 사용자마다 초기 설정이 다소 번거롭고 즉각적인 활용성이 떨어질 수 있다. 마지막으로, edge device computational efficiency 한계로 인해 video generation과 같은 복잡한 작업에서 latency가 발생할 수 있다.
이를 개선하기 위해, 연구진은 조명 변화와 반사 조건에 강한 lighting and reflective robustness를 강화하고, depth information and 3D manipulation 기능을 추가하여 3D 상호작용의 현실감을 높일 계획이다. Personalization automation을 통해 초기 설정을 최소화하고, edge device에서의 연산 효율성을 개선하여 다양한 AR 응용 분야에서 GazeGen이 원활히 활용될 수 있도록 할 예정이다.
이러한 개선을 통해 GazeGen은 향후 다양한 AR 및 VR 환경에서 더 직관적이고 강력한 gaze-driven interaction을 구현하는 것을 목표로 하고 있다.
결론 및 느낀 점
이 논문은 시선 추적을 통해 AR 환경에서 직관적인 사용자 경험을 제공하는 새로운 가능성을 보여준다. 이는 내가 진행 중인 시선과 같은 비언어적 신호를 인식해 사람의 무의식적이고 비언어적인 의도를 파악하고, 이를 통해 더 나은 사용자 경험을 제공하려는 연구와 밀접하게 맞닿아 있기도 하다.
GazeGen의 DFT Gaze 모델을 통한 경량화된 시선 추적은 AR 글래스와 같은 제한된 연산 환경에서도 실시간으로 사용자의 시선 정보를 활용할 수 있게 하여, 비언어적 신호를 기반으로 사용자 경험을 확장할 가능성을 제시한다. 단순히 시선을 추적하는 데 그치지 않고, gaze-driven content manipulation과 video generation을 통해 시선을 의도를 전달하는 도구로 확장한 점은, 비언어적 신호를 통해 사용자의 무의식적 의도를 파악하고 반응하는 시스템 설계에 유용한 통찰을 제공한다.
이러한 점에서 이 논문은 비언어적 신호를 통한 사용자 경험 증진 연구에 중요한 참고 자료가 될 것이라고 생각한다.

댓글