TL;DR
이 솔루션은 ICCV 2023 Egocentric 3D Hand Pose Estimation Challenge에서 1위를 차지한 기술로, 1인칭 시점에서 손의 위치와 자세를 3D로 추정하는 문제에 대해 높은 정확도를 달성했다. 주요 접근법은 Pre-trained Vision-Transformer(ViT)를 활용한 특징 추출과 다양한 Augmentation 기법을 적용한 것이다. 특히, Multi-view 데이터를 활용해 Occlusion 문제를 해결하고, Smoothing 기법과 앙상블을 통해 성능을 최적화했다. 최종 성능은 12.2mm MPJPE를 기록했으며, ViT와 ConvNext를 결합한 Multi-model fusion으로 정확도를 높였다.
1st Place Solution of Egocentric 3D Hand Pose Estimation Challenge 2023
이번 게시글에서는 ICCV Egocentric 3D Hand Pose Estimation Challenge 2023에서 1위를 한 솔루션을 분석해 보도록 하겠다. 해당 대회는 AssemblyHands 데이터셋을 활용하여 Egocentric 3D hand pose estimation을 수행하는 대회이다. 여기서 Egocentric 이란, 별도의 외부 view를 두는 Exocentric과 대비되는 용어로 '1인칭 시점'이라고 이해하면 된다. 즉, Hand pose estimation의 대상이 되는 손을 가진 사람의 시점을 의미하는 것으로, AR 헤드셋을 쓰고 자신의 손을 바라보고 있는 것을 상상하면 이해가 쉽다.
Introduction
3D Hand Pose Estimation은 이름 그대로 손의 위치 및 자세를 3D로 추정하는 기술을 의미한다. 이 기술은 지능형 로봇 개발과 가상현실(VR)·증강현실(AR) 등 Gesture interaction application의 핵심 기술로, 손동작을 통한 기계 또는 가상 물체의 조작, 수화 자동 인식 및 번역 등 다양한 분야에 활용될 수 있는 기술이다.
하지만 인간의 손은 여러 개의 관절을 가지고 있으며 높은 자유도(DOF, Degree Of Freedom)를 가지기 때문에 이를 정확히 추정하는 것은 어려운 일이다. 게다가 단일 Egocentric view만을 이용할 경우 손의 위치 및 동작이 가려지는 Occlusion 문제에 취약하다는 문제 또한 발생한다.
이를 해결하기 위해서 사용되는 방법론은 크게 두 가지로 나눌 수 있다. 하나는 가시점(visible points)의 정확도를 향상하는 방법이고 또 다른 하나는 폐색점(occlusion points)의 안정성을 높이는 방법이다. 전자의 경우 일반적으로 반복적인 조정을 통해 가시영역의 key points를 정확하게 위치시키기 위해 multi-stage model을 활용하거나, 손의 골격과 같은 사전에 알 수 있는 구조적 정보를 활용하여 동작 모델링의 모호성을 줄이는 방식을 주로 선택하였다. 또 후자의 경우 Exocentric view 등 다중 시점의 이미지를 활용하여 공간적인 정보를 얻음으로써 Occlusion에 의한 영향을 줄이거나 다중 프레임 간의 key point 정보를 활용하여 일시적인 Occlusion에 대응하는 방식을 사용해 왔다. 또, Ziani et al. 2022에서는 Unsupervised hands data를 pre-training에 활용함으로써 별도의 추가 합성 데이터나 특별한 구조 없이도 성능을 성공적으로 올리기도 하였다.
이번 대회에서 1위를 한 솔루션의 저자들은 이러한 기존의 접근법들을 종합적으로 사용하였는데, 그중에서도 특히 Pre-trained Model의 가능성에 집중하였다. 해당 솔루션에서는 3D keypoints prediction의 정확도를 높이는 접근법을 사용하였다. 이들은 Pre-trained Vision-Transformer(이하 ViT)를 Feature extraction backbone으로 사용하였으며 이와 함께 간단한 3D skeleton decoder를 사용하여 높은 정확도를 달성했다.
Methods
해당 컴페티션은 외부 공개 데이터셋의 사용을 허가하고 있기 때문에 저자들은 Multi-view Egocentric 이미지 데이터셋인 AssemblyHands 뿐만 아니라 Green screen을 배경으로 하여 다양한 배경 이미지로의 변환이 자유로운 Single-view color 이미지 데이터셋인 Freihand와 물체를 잡는 손을 촬영한 DexYCB, 그리고 Multiple pose와 viewpoints로 합성된 데이터셋인 CompHand 데이터셋을 학습에 활용했다(결과적으로, 이러한 외부 데이터셋의 활용은 0.2mm의 점수 향상을 이루어냈다).
저자들은 어안(fisheye) 렌즈로 촬영된 이미지의 왜곡 보정(undistortion operarion) 과정에서 가장자리 부분이 과하게 늘려져 있는 것을 확인하였다. 이러한 왜곡은 일부만으로도 모델이 깊이 추정을 잘하지 못하게 만들었기에 Warp perspective 연산을 통해 이러한 왜곡을 줄였다. 이들은 또한 모델의 강건성을 위해 입력 이미지에 Augmentation 또한 적용하였다. 이러한 Augmentation은 학습 데이터는 물론, 추론의 정확도를 높이기 위해 테스트 단계에서도 사용되었다. 다음은 저자들이 적용한 Augmentation 기법들이다.
- 각 채널을 0.6 ~ 1.4 사이 랜덤 스케일로 multiply 하여서 channel noise 적용
- Occlusion을 simulate 하기 위해 0.5 확률로 Random mask 적용
- 밝기 대비 조정 적용
모델의 구조와 관련해서는 컴퓨터 비전 Task에서 강력한 성능을 보이는 ViT를 사용했다. 이들은 Masked Auto-Encoder(MAE) 방식으로 Pre-trained 된 ViT를 Feature extractor로 활용했다. ViT Block은 다중 풀링 레이어와 함께 사용되어 Multi-scale 입력으로부터 hand feature 추출을 수행하였고 이러한 feature들은 Multi-level feature fusion 연산을 통해 합쳐졌다. 최종적으로 이들은 이렇게 합쳐진 feature로부터 2D keypoints와, 손목 부분에 존재하는 Root를 기준으로 하는 Root-relative 3D keypoints 및 Root depth를 추정하기 위해 간단한 MLP 헤드를 사용했다.
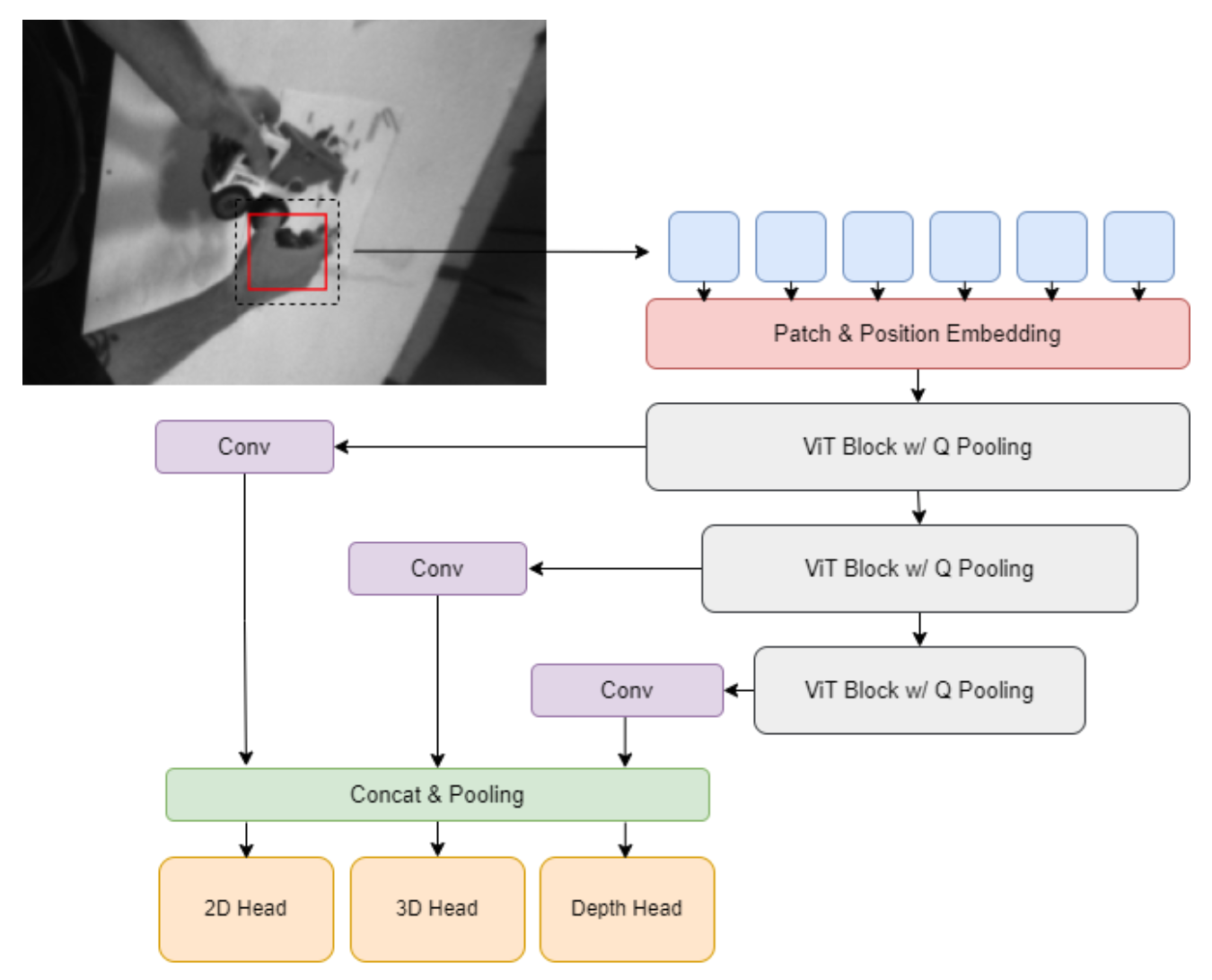
모델의 최종 출력이 각각의 카메라 좌표계에 존재하므로 Multi-view merge strategy를 이용하여 최종적인 글로벌한 좌표값을 얻었다. 이때 사용한 전략은 각각의 view에 대해 MPJPE(Mean Per Joint Position Error)를 계산한 후 가장 낮은 MPJPE를 가지는 두 결괏값을 선택하는 것이었다. 만약 사전에 설정한 임계값보다 두 결과의 MPJPE가 낮으면 둘의 평균을 최종 결과로 계산하였고, 그렇지 않은 경우 이전 프레임의 결과와 함께 PA-MPJPE가 낮은 결과를 선택하였다. 이렇게 Multi-view merging 연산을 수행한 후 최종적으로 각 영상에 Savitzky-Golay filter를 적용하여 offline smoothing을 수행하였다.
Results
실험은 8개의 2080Ti GPU를 사용하여 진행되었으며 각 배치마다 128장의 이미지가 사용되었다. 옵티마이저로는 AdamW를 사용하였으며 초기 learning rate로는 1e-4를 사용했다. 이 learning rate는 1e-2의 Weigth decay를 갖는 Cosine scheduler로 학습이 진행됨에 따라 조정되었다.
먼저 이들은 세 개의 ViT 모델과 한 개의 ConvNext 모델을 학습시켰다. 각 모델에 대해 Multi-view 예측 결과를 Egocentric result로 aggreagate 한 이후 Smoothing을 적용하였다. 여기에 서로 다른 Multi-scale crop을 적용함으로써 비디오마다 서로 다른 크기의 손의 크기에 적절히 대응하도록 하였다. 마지막으로 이들은 세 개의 ViT 모델의 결과를 앙상블 하고 ConvNext의 결과를 fusion 하였다.
각 단계를 분리해서 보았을 때, Multi-view aggregation과 smoothing을 한 결과 13.6의 MPJPE를 달성하였으며 여기에 Multi-scale crop을 추가함으로써 0.7mm만큼의 성능 향상을 이루었다. 이후 ViT를 앙상블함으로써 0.2mm만큼의 향상을 보였으며 ConvNext 결과를 fusion 함으로써 0.5mm의 개선을 얻어 최종적으로 12.2 MPJPE를 달성하였다.
| Exp Number | Method | MPJPE |
| Exp 1 | Hiera + Multi-view + Smoothing | 13.6 |
| Exp 2 | Exp 1 + Multi-scale crop | 12.9 (-0.7mm) |
| Exp 3 | Exp 2 + Multi-model fusion | 12.7 (-0.2mm) |
| Exp 4 | Exp 3 + ConvNext fusion | 12.2 (-0.5mm) |
Conclusion
해당 솔루션은 기존의 연구들을 잘 분석하고 적절하게 조합하여 실험을 수행한 결과로 보인다. Multi-scale의 feature를 사용하였으며 최근 제안된 빠르고 강력한 ViT 아키텍처인 Hiera를 Backbone으로 사용하였다. 또한 태스크의 특성에 맞는 Augmentation 기법을 적절히 사용하였으며 TTA(Test-Time Augmentation)를 적용함으로써 모델의 추론 성능을 더 끌어올리고자 하였다.
다만, 사용 기법에 대한 명확한 근거가 부족하며 각각의 component에 대한 설명이 빈약한 점이 아쉬움으로 남는다.

댓글