AI 에이전트 구현을 위한 7가지 워크플로우 패턴
AI 에이전트는 작업을 동적으로 계획하고 실행할 수 있다. 이러한 에이전트를 디자인하고 구현할 때는 문제 해결 방식에 따라 적절한 디자인 패턴을 선택해서 활용해야 한다. 이번 게시글에서는 이러한 디자인 패턴 중 가장 흔하게 사용되는 7가지 형태를 리뷰하도록 하겠다.
* 참고로 이 게시글에 있는 모든 코드는 수도코드에 가깝게 추상화된 것으로, 바로 사용할 수는 없다.
7가지 워크플로우 디자인 패턴은 다음과 같다.
- 프롬프트 체이닝
- 라우팅(핸드오프)
- 병렬 처리
- 툴 유즈 패턴
- 오케스트레이터-워커 패턴
- 리플렉션 패턴
- 멀티 에이전트 패턴
프롬프트 체이닝
프롬프트 체이닝(Prompt Chaining) 패턴은 특정 입력에 대한 최종 출력을 얻기 위해 일련의 단계를 차례대로 진행하며 LLM을 호출하는 방식이다. 사슬(Chain)처럼 각 단계의 출력이 다음 단계의 입력으로 사용되는 구조로 구성되어 있으며, 이를 통해 복잡한 하나의 작업을 예측 가능한 여러 개의 단계로 분해하여 해결할 수 있다.
에이전트 시대 이전, 대부분의 워크플로우 자동화가 동작하던 방식과 유사하며, 디자인에 앞서 각 단계(노드라고 부르겠다)를 분해하고 정의하는 것이 필요하다. 거의 모든 작업은 이 패턴으로 설계가 가능하지만 효율성, 안정성 등을 이유로 다른 패턴들이 등장했다. 속도 및 비용, 구현 난이도는 다른 패턴에 비해 일반적으로 우수한 편.
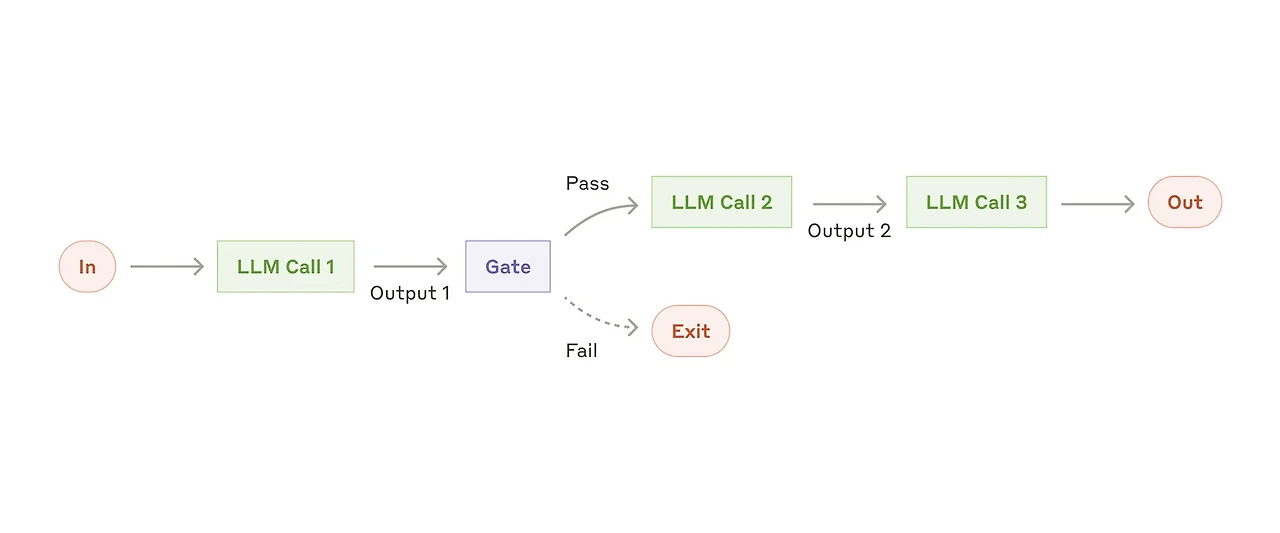
예시: 다단계 ETL 처리 파이프라인, 뉴스레터 큐레이션 등
def prompt_chainning_pattern(initial_input: str, prompt_chain: List[str]) -> List[str]:
response_chain = []
response = initial_input
for i, prompt in enumerate(prompt_chain, 1):
# 단계별 프롬프트와 이전 단계 응답을 연결
final_prompt = f"""{prompt}
초기 입력: {initial_prompt} # (선택) 맥락 유지를 위해 초기 입력 유지
응답 시 참고할 내용: {response}
"""
response = llm_call(final_prompt)
response_chain.append(response)
return response_chain라우팅(핸드오프)
라우팅(Routing) 혹은 핸드오프(Hand-off) 패턴은 입력을 분석하여 여러 경로 중 하나의 경로(다운스트림 작업)를 선택하여 전달하는 방식이다. 대표적으로 사용자의 쿼리에 따라 서로 다른 데이터 소스를 사용하는 Adaptive RAG에 사용된다. 이 외에도 필요로 하는 작업에 따라 서로 다른 워크플로우로 연결해 준다던지, 작업의 난이도에 따라 적절한 사이즈의 모델을 선택한다든지 하는 방식으로 사용이 가능하다.
환경에 따라 스스로 목표를 세우고 전략을 바꾸며 동작하는 Agentic AI와 혼동될 수 있지만, 라우터는 결정만 담당(보통, 기준이 사전에 설정되어 있음)하고 이후 실행은 해당 경로에 위임된다는 점이 차이라고 볼 수 있다.
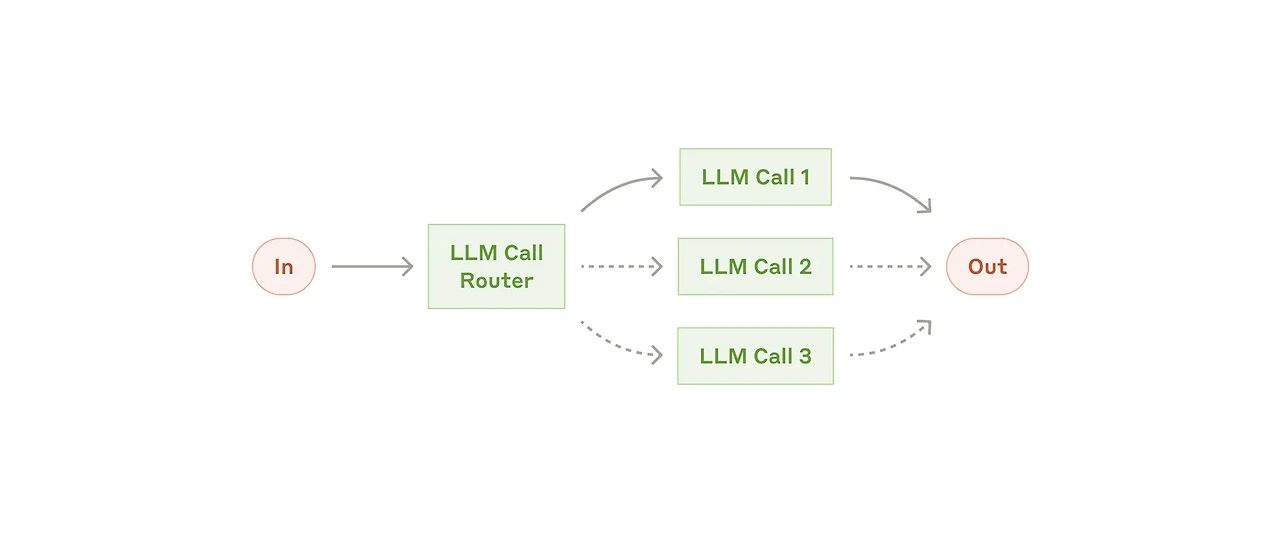
예시: 고객 지원 시스템, 계층형 LLM
def routing_pattern(user_prompt: str) -> str:
router_prompt = f"""
사용자 입력: {user_prompt}
위 질문에 대해 가장 적절한 유형을 하나 골라서 응답하세요.
단답형으로 유형만 출력하세요.
- 일상: 일반적인 대화, 일정 짜기, 정보 요청 등
- 빠른: 간단한 계산, 단답형 질문, 간단한 명령 등
- 코딩: 코드 작성, 오류 디버깅 등
"""
routing_result = llm_call(router_prompt).strip()
return routing_result
# category = routing_pattern(query)
# final_llm_call = ROUTING_MAP.get(category)
# response = final_llm_call(query)병렬 처리
병렬 처리(Parallelization)는 하나의 작업을 동시에 처리되어야하는 여러 개의 작업으로 나누고 각각의 응답을 받은 뒤 이를 병합하여 사용하는 패턴이다. 여러 LLM 혹은 노드의 응답은 어그리게이터(Aggregator)가 취합하여 최적 응답을 생성하는 방식으로 동작한다. 각 노드는 서로 의존성을 가지지 않는 각각의 하위 작업들을 병렬적으로 수행하는 형태일 수도 있고, 같은 작업을 여러 맥락으로 실행하면서 여러 개의 응답을 받고 이를 종합하여 결론을 내리는 형태로 디자인할 수도 있다(like 랜덤포레스트).
기본적으로 병렬의 이점을 이용하기 때문에 직렬 처리 대비 처리 속도가 빠르며 강건성이 필요한 경우에도 자주 사용된다. 각 노드 중 하나 이상의 응답에서 에러가 발생했을 때 이를 어떻게 처리할지도 디자인이 필요하다.
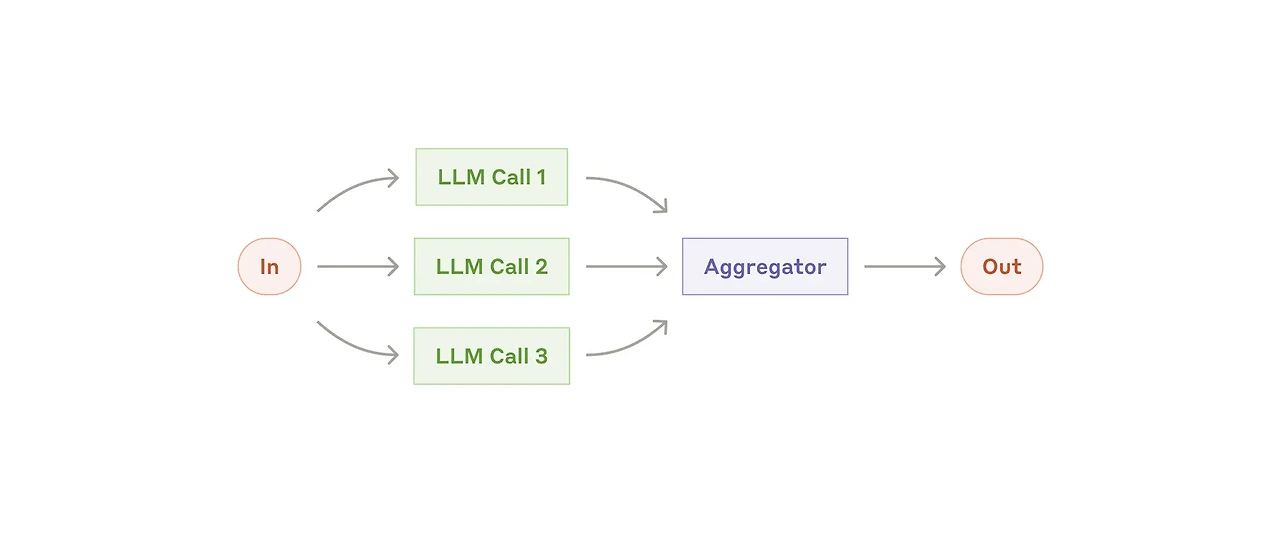
예시: 병렬 검색 RAG, 멀티 페르소나 실험
async def parallel_pattern(prompt_settings):
# 병렬처리 패턴은 주로 비동기로 구현됨
# 비동기 LLM 호출 작업 목록 생성
tasks = [
llm_call_async(
prompt['user_prompt'],
prompt['system_prompt'],
prompt['model']
for prompt in prompt_settings
]
# 작업 목록 실행 및 aggregation
responses = await asyncio.gather(*tasks)
return responses툴 유즈 패턴
툴 유즈(Tool-use) 패턴은 외부 함수나 API를 호출하여 문제를 해결하는 것이 필요한 상황에서 적용할 수 있는 패턴이다. 이 패턴은 함수 호출(Function Calling), 도구 사용(Tool Use), 더 나아가서 작년 한 해 핫하게 다뤄졌던 MCP(Model Context Protocol)까지 포함한다고 볼 수 있다.
주로 하나의 중심 노드(또는 에이전트 역할의 컴포넌트)가 입력을 받아 어떤 도구(함수, API 등)를 사용할지 결정하고, 도구의 실행 결과를 반영하여 응답을 생성하는 방식으로 동작한다. 이 과정은 단발적일 수도 있고, 필요에 따라 제한된 반복(Loop) 구조를 가질 수도 있으며, 이러한 점에서 전형적인 에이전트 패턴과 구조적으로 유사한 면이 있다. 다만, 결정과 실행이 동일한 루프 내에서 이루어진다는 점에서, 결정만 수행하고 실행을 다른 경로에 위임하는 라우팅 패턴과는 구분된다.
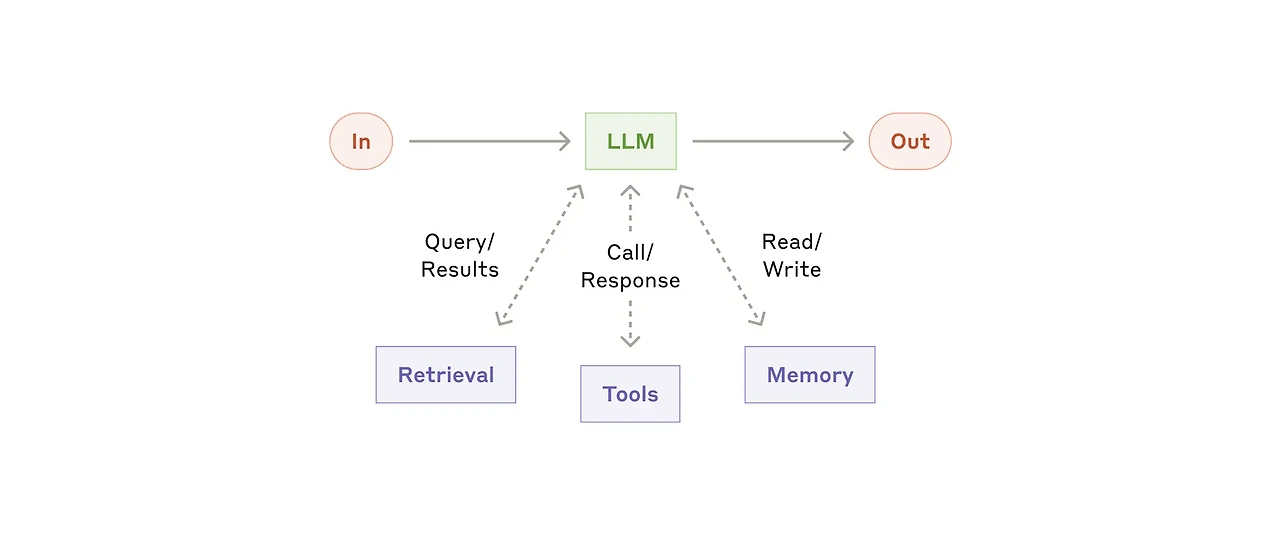
예시: 외부 API를 이용한 회의실 예약 서비스, 코딩 에이전트
tool_function = {
"name":"",
"description":"",
"parameters": { ... }
}
def tool_function(properties):
# tool implementation
return results
tools = types.Tool(function_declarations=[tool_function])
def tool_use_pattern(user_prompt: str, tools: List) -> str:
llm_instance.bind_tools(tools)
response = llm_call(user_prompt)오케스트레이터-워커 패턴
오케스트레이터-워커(Orchestrator-Worker) 패턴은 오케스트레이터가 복잡한 작업을 입력받아 적절한 하위 작업으로 분할하고 이를 각각 전문적인 하위 에이전트인 워커에 할당하는 방식으로 동작하는 패턴이다. 오케스트레이터는 1차적으로 쿼리를 해결하기 위한 플랜을 작성하는데 이 플랜에는 어떤 작업을 어떤 에이전트에게 위임할지에 대한 내용도 함께 기록된다.
라우팅 혹은 병렬 처리와도 유사하지만, 다음 노드로의 직접적인 라우트를 통해 작업을 전달한다는 개념보다는 생성된 플랜을 바탕으로 하위 작업이 실행되는 형태라는 점에서 라우팅 패턴과 구분되며, 사전에 정의된 하위 작업이 아니라 오케스트레이터가 작성한 플랜에 따라 유연하게 수행된다는 점에서 병렬 처리와도 차이를 보인다. 각 워커의 작업 결과물(=출력)은 다시 어그리게이터로 모이고 최종 응답이 생성된다.
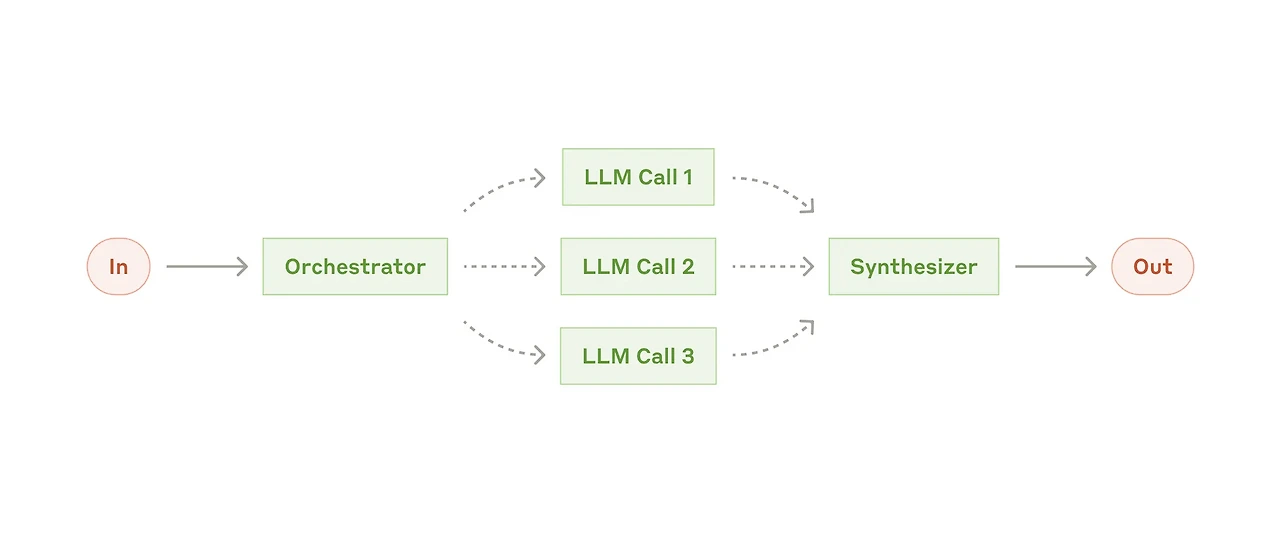
예시: 딥 리서치, 여행 계획 플래너
# 오케스트레이터가 하위 작업 생성
def get_orchestrator_response(user_prompt):
orchestrator_prompt = f"""
다음 user_prompt를 분석한 뒤, 이를 3개 이내의 관련 하위 질문으로 분해하세요.
{user_prompt}
응답은 별도 설명 없이 JSON 형태로 제공하세요.
json```
[
{{
"question":"하위 질문 1",
"description": "하위 질문의 요지와 의도 설명"
}},
...
]
"""
return llm_call(orchestrator_prompt)
orchestration_responses = get_orchestrator_response(user_prompt)
prompt_settings = build_prompt_settings(orchestration_responses)
async def get_worker_response(prompt_settings):
tasks = [
worker_llm_call(
prompt['user_prompt'],
prompt['system_prompt'],
prompt['model']
)
for prompt in prompt_settings
]
responses = await asyncio.gather(*tasks)
for prompt, ans in zip(prompt_settings, raw_responses):
bundled.append(
{
"question": prompt.get("question") or prompt.get("user_prompt"),
"answer": ans,
}
)
return responses
worker_responses = await get_worker_response(prompt_settings)
def aggregator_process(worker_response):
aggregator_prompt = (
"다음은 사용자 입력을 하위 질문으로 나누고 받은 응답입니다.\n"
"이 내용을 모두 종합해서 답변을 제공하세요.\n"
f"사용자 입력: {user_query}\n"
"하위 질문 및 응답:\n"
)
for i, response in enumerate(worker_response, 1)
aggregator_prompt += f"하위 질문 {i}) {response['question']}\n"
aggregator_prompt += f"응답 {i}: {response['answer']}\n"
return llm_call(aggregator_prompt)리플렉션 패턴
리플렉션(Reflection) 패턴은 출력에 대한 평가를 진행하고 평가 기준을 못맞춘 경우 피드백 루프를 돌아 반복적으로 응답을 생성하는 형태의 패턴이다. 크게 평가 에이전트(Evaluator)와 최적화 에이전트(Optimizer)로 구성되며, 평가 에이전트가 응답에 대해 점수와 그 이유를 생성하면 이를 최적화 에이전트가 다시 입력으로 받아 최적화된 응답을 다시 제공하는 형태로 동작한다. 이러한 과정은 평가 기준을 만족할 때까지 반복되는데, 최대 반복 횟수(Max retry, cut-off)를 지정하지 않거나 평가 기준을 너무 빡빡하게 잡을 경우 무한 루프에 빠질 우려가 있어 주의해야 한다.
LLM-as-a-Judge, Self-refinement 등의 키워드와 함께 언급되는 대표적 패턴 중 하나이다.
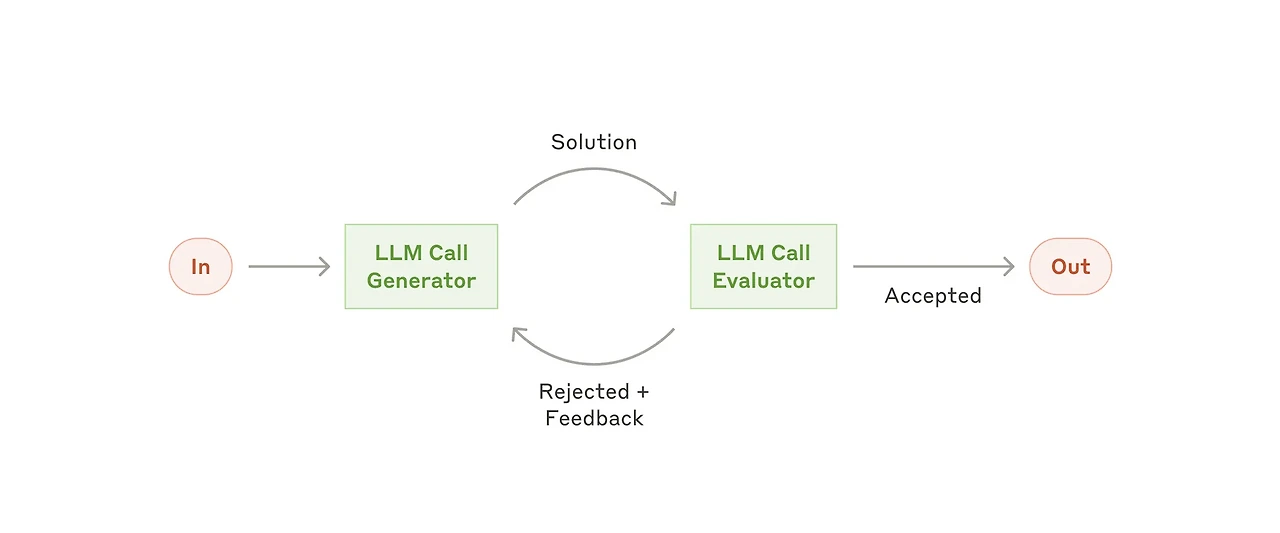
예시: 코딩 에이전트, 보고서 작성 에이전트
def reflection_pattern(user_prompt, max_retries=5):
feedback_history = ""
for i in range(max_retries):
inter_result = execute(user_prompt, feedback_history)
evaluation = evaluate(user_prompt, inter_result)
if "PASS" in evaluation:
result = inter_result
feedback_history += f"[trial {i+1}]\n- 중간 결과: {inter_result}\n- 평가 피드백: {evaluation}"
return result멀티 에이전트 패턴
멀티 에이전트(Multi-agent) 패턴은 이름에서부터 알 수 있듯이, 여러 개의 서로 다른 역할을 수행하는 에이전트들이 공동의 목표를 달성하기 위해 상호작용하며 결과물을 만들어내는 패턴이다. 각 에이전트는 특정 역할이나 관점을 담당하며, 이들 간의 협력과 조율을 통해 단일 에이전트로는 해결하기 어려운 복잡한 문제를 다룰 수 있다.
LLM 기반 멀티 에이전트 시스템에서는 에이전트 간 대화와 작업 흐름이 의도한 구조대로 전달되고 유지되는지가 중요한 설계 요소가 되며, 이를 위해 PM과 유사한 역할을 수행하는 슈퍼바이저(Supervisor or Coordinator) 에이전트를 활용하여 에이전트 간 상호작용을 통제, 조절하거나 다음 행동을 결정하도록 설계하기도 한다.
멀티 에이전트 패턴에서는 에이전트 간 상호작용 경로의 길이인 Depth가 깊어질수록 각 에이전트가 수행하는 역할 및 책임이 명확한 서브그룹 혹은 클러스터 단위로 운영되는 것이 안정적인 동작에 유리하다. 이러한 설계를 통해 상호작용이 길어짐에 따라 커지는 오류 전파의 위험 등을 줄이고 각 에이전트들의 전문성을 잘 활용할 수 있다.
슈퍼바이저가 다른 에이전트로 작업을 연결하는 방식은 라우팅 패턴과 유사해 보일 수 있으나, 단발적으로 경로를 선택해 위임하는 라우팅과 달리, 각 에이전트의 실행 결과를 다시 받아 전체 흐름을 조정한다는 점에서 차이가 있다. 또한 오케스트레이터-워커 패턴과 유사하게 중앙 관리자가 존재하지만, 하위 작업을 분해하여 병렬적으로 위임하는 구조가 아닌, 에이전트 간 상호작용과 협업 자체를 관리한다는 점에서 구분된다.
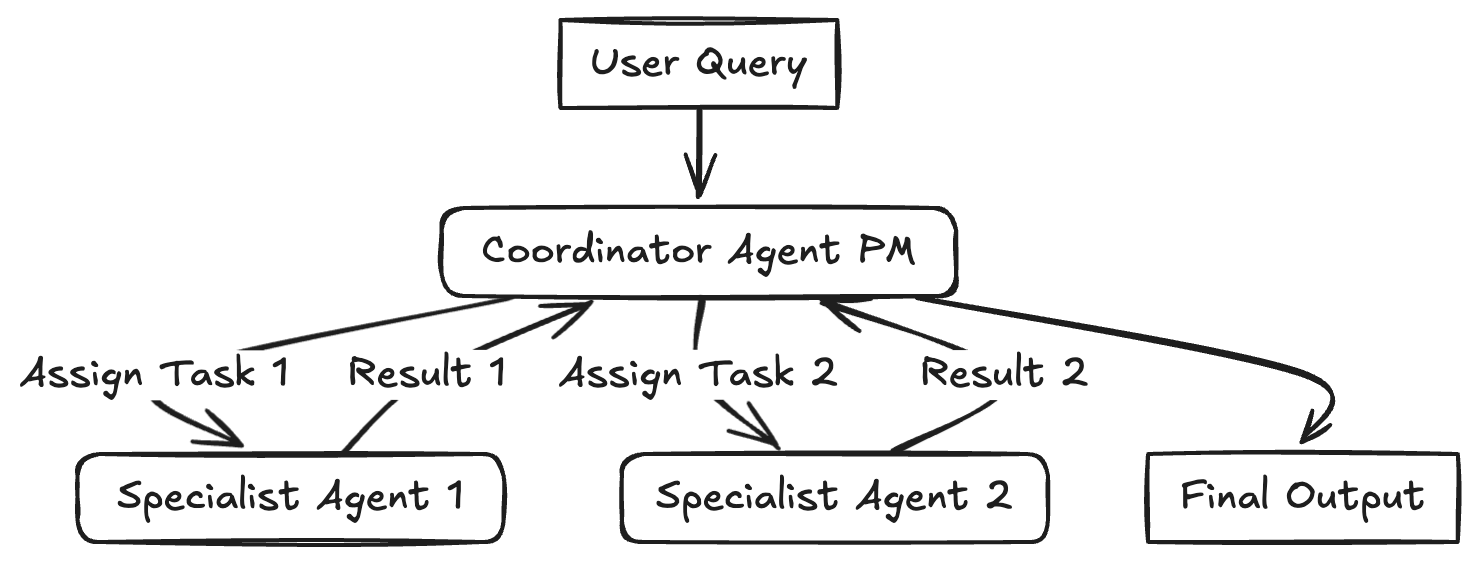
예시: 브레인 스토밍, 가상 사용자 실험
정리
이처럼 AI 에이전트를 구현하기 위한 워크플로 디자인 패턴에는 여러 가지 형태가 존재한다. 여기서 주의할 점은, 실제 구현에서는 각 패턴을 하나만 선택하는 것이 아닌, 두 가지 이상의 패턴을 적절히 조립하여 사용하는 것이 일반적이라는 것이다. 이를 위해서는 블록이 되는 각 패턴을 정확히 이해하고 적절한 위치에서 사용하도록 디자인하는 것이 필수적이다.
사진 출처:
[1] https://www.anthropic.com/engineering/building-effective-agents
[2] https://www.philschmid.de/agentic-pattern#multi-agent-pattern
'ML&DL > AI 에이전트' 카테고리의 다른 글
| AI Agent의 개념과 기본 구현 방법 (0) | 2025.02.23 |
|---|---|
| LLM Agent의 Thought-Action-Observation Cycle (0) | 2025.02.23 |
| LLM 에이전트의 도구 사용 (0) | 2025.02.22 |
| Message와 Special Token (0) | 2025.02.15 |
| Agent의 두뇌, LLM에 대해서 알아보자 (1) | 2025.02.14 |

댓글