외부로부터 수집되는 데이터는 일반적으로 머신러닝 모델이 사용할 수 없는 형식인 경우가 많다. 따라서, 데이터를 모델이 사용할 수 있는 형태로 처리하는 과정이 필요한데, 이를 데이터 전처리라고 한다.
데이터는 일관적인 전처리 과정을 통해 처리되는 것이 일반적이며, 이를 위해 보통 데이터 검증 이후 전처리 과정이 수행된다.
머신러닝 파이프라인의 일부인 데이터 전처리
TFX는 데이터 전처리를 위한 컴포넌트인 TensorFlow Transform(TFT)을 지원한다. 이를 이용하면 전처리 단계를 텐서플로우 그래프의 형태로 구성할 수 있다. 다만 이러한 방식은 다소 오버헤드가 발생할 수 있기 때문에 실험단계에서의 사용은 권장하지 않는다.
데이터 전처리 통합의 필요성
TFT는 데이터 전처리 단계를 텐서플로우로 구현해야 한다는 점에서 TFX 컴포넌트 중 가장 배우기 어려운 라이브러리 중 하나라고 평가받는다. 하지만 TFT를 장착한 머신러닝 파이프라인에서 데이터 전처리를 표준화하면 전체 데이터셋의 콘텍스트에서 데이터를 효율적으로 처리할 수 있고 전처리 확장 또한 간편하며 잠재적인 학습-서빙 왜곡을 방지할 수 있다.
전체 데이터셋 콘텍스트에서 데이터 전처리
데이터를 전처리하는 과정은 종종 전체 데이터셋의 콘텍스트를 요구한다. 예를 들어 수치형 데이터를 정규화하는 과정을 생각해보자. 이 경우 (스케일링 방식에 따라 약간의 차이가 있지만) 데이터의 최댓값, 최솟값 혹은 평균과 분산 등 전체 데이터에 대한 기준값이 필요하고, 이를 이용해 정규화를 진행하는 두 단계의 과정을 거친다. 즉, 먼저 기준을 설정하고 그 기준에 맞춰 각 피처를 변환하는 과정이 필요한 것이다.
전처리 단계의 처리 규모 조정
TFT는 내부적으로 아파치 빔을 사용하여 전처리 알고리즘을 수행하므로 필요에 따라 아파치 빔 백엔드에서 전처리 배포가 가능하다. 아파치 빔은 구글 클라우드의 데이터 플로우나 아파치 스파크, 아파치 플링크 클러스터 등에 접근할 수 없는 경우 Direct Runner 모드로 실행된다.
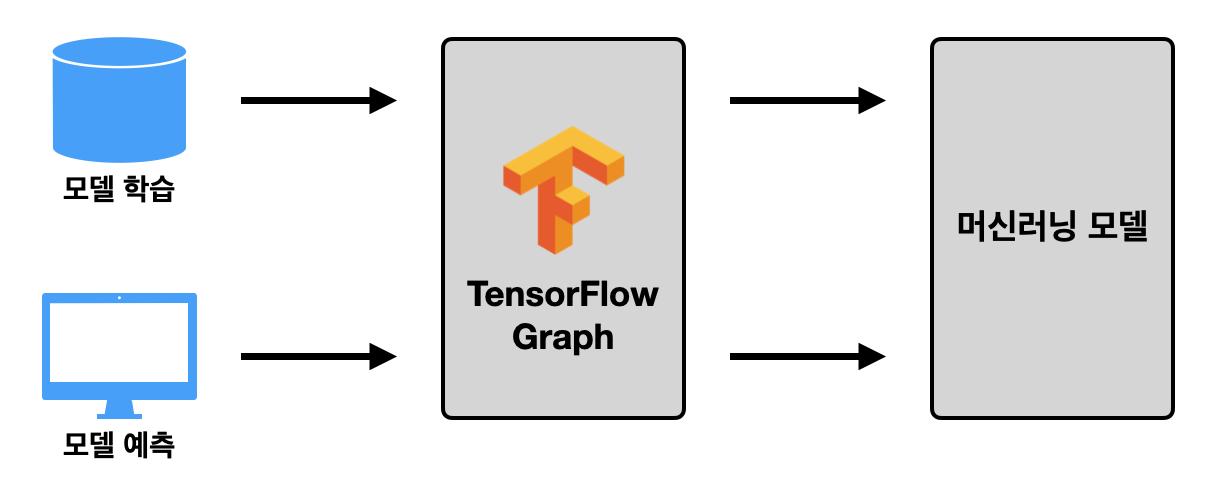
학습-서빙 왜곡 방지
TFT는 전처리 단계 텐서플로우 그래프를 생성하고 저장한다. 이 그래프는 모델 라이프사이클의 예측 단계에서 해당 모델이 학습에 사용한 모델과 같은 전처리 프로세스를 가질 수 있도록 하여 학습과 서빙 간의 왜곡을 방지한다.
학습-서빙 왜곡이란 모델 학습 중에 사용한 전처리 단계가 예측에 사용되는 단계와 일치하지 않을 경우 학습-서빙 왜곡이 발생한다. 일반적으로 머신러닝 모델의 학습은 파이썬 노트북 상에서 이뤄지거나 스파크에서 처리될 때가 많음에 반해 서빙된 모델에서는 데이터가 API 단계에서 처리되어 모델에 전달되는 방식이 주를 이룬다. 이 경우 두 프로세스 간 불일치가 일어날 확률이 존재하며, 이는 일관적인 모델 적용을 어렵게 할 수 있다. 일반적인 머신러닝 모델 설정 TFT를 이용한 왜곡 방지 TFT를 사용하여 전처리 텐서플로우 그래프를 배포하면 두 과정에 대한 전처리 단계가 일관적으로 적용될 수 있고, 이는 모델 왜곡을 방지하며 배포에 필요한 조정량을 줄여 배포를 단순화한다. TFT를 사용한 전처리 일관화
전처리 단계와 모델을 하나의 아티팩트로 배포
위에서 설명하였듯이, 전처리 단계와 모델을 모두 배포하는 것은 왜곡을 방지하고 일관성 있는 결과를 낼 수 있게 한다. 이때 머신러닝 파이프라인 내에서는 두 단계가 하나의 아티팩트로 포함되는 것이 좋다. 이렇게 하면 모델이 예측을 수행하는 동안 해당 과정의 일부로 데이터를 불러와 전처리를 할 수 있는데, 이는 클라이언트 측이 아닌 서버 측에서 전처리가 수행되도록 하며 클라이언트(앱, 웹 등)의 개발을 단순화한다.
파이프라인에서 전처리 결과 확인
TFT로 데이터 전처리를 구현한 뒤 파이프라인을 통합하면 전처리가 완료된 데이터에 대하여 통계를 확인할 수 있다는 장점이 있다. 이를 통해 데이터가 모델 학습에 필요한 요구조건을 충족하는지 확인할 수 있고, 이는 모델 정확도에 큰 영향을 줄 수 있다.



댓글